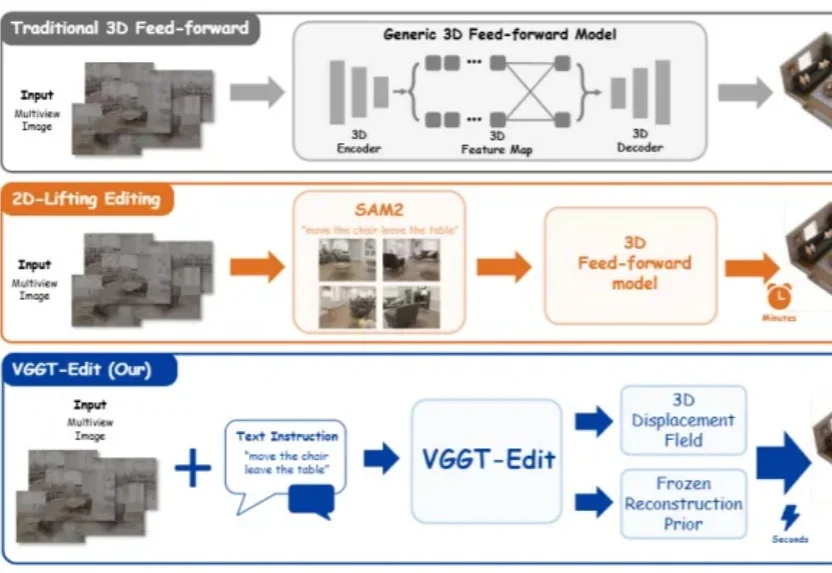
Sengine:三个年轻的中国创始人,让 AI 直接生成 3D 世界
Sengine:三个年轻的中国创始人,让 AI 直接生成 3D 世界今天要分享的公司是:Sengine,生境科技,之前我也分享过一家国内做 3D 的 AI 公司,但 Sengine 和 VAST 完全不是一个产品路径,后面会分析。2026 年,Forbes 30 Under 30 Asia 的 AI 榜单里,有一家来自深圳的公司:Sengine Technology,生境科技。
来自主题: AI资讯
7631 点击 2026-07-01 10:40